Disaster Recovery
Disaster recovery is a fancy way of saying "all other measures have failed, we need to restore from backups". Too many organizations end up paying the ransom after a ransomware attack, so it is obvious that organizations neglect disaster recovery. This section discusses how to go from "we make backups – and hope for the best" to "we know exactly what to do in case of a disaster".
Why Disaster Recovery Training?
Airline pilots train countless failures in a flight simulator every year. Why? For two reasons. First, airline incidents leave little room for thinking and often need to be executed from memory. Second, airline incidents are rare, hence it is impossible "to be ready for them" except by preparing.
Although Kubernetes technology is rapidly maturing, we noticed that platform teams are often denied the training they need to safely recover from a disaster. I often ask teams "So how did your last disaster recovery drill go?" and the room stays silent … uncomfortably silent. Although training for an unlikely scenario – i.e., a disaster – may seem like a waste of time, here is why "we make backups" is simply not enough:
- Incidents are rather stressful. The team’s stress level can be reduced by making sure that there is always a reliable, known-good last resort to resolving any incident: disaster recovery.
- Disaster recovery is complex and stressful. And Kubernetes admins are not very smart when they are stressed. Hence, most disaster recovery needs to be executed by mechanically following a runbook and/or executing scripts. But how do you know that the runbook and/or scripts are up-to-date? Disaster recovery training.
- Disaster recovery training boosts team confidence and morale. This happens naturally as a consequence of having eliminated the stress associated with disaster recovery.
- Disaster recovery training allows you to measure the time from a disaster’s start to the time when all systems are completely recovered. (See discussion on RTO below.)
- Some data protection regulations make it clear that disaster recovery training is mandatory (e.g., Swedish Patient Data Ordnance – HSLF 2016:40). Hence, if none of the arguments above convinced you, perform disaster recovery training to please your auditors and avoid fines.
Disaster Recovery Primer
Let us go deeper into what disaster recovery is. Perhaps the best way to do this is to contrast it with business continuity. Business continuity means taking measures to prevent incidents from becoming a disruption. For example, it is known that servers fail. Hence, by adding enough redundancy – e.g., running 3 Kubernetes control-plane Nodes – you ensure that a routine event does not cause downtime.
Disaster recovery can be seen as a way to deal with the residual risk of business continuity. No matter how hard you try, there will always be events for which you are not prepared, either due to ignorance, ineptitude or cost. For example, no matter how many safeguards you put in place and how many certificates you shower over your team, human error – perhaps of someone outside your platform team – will always be a factor.
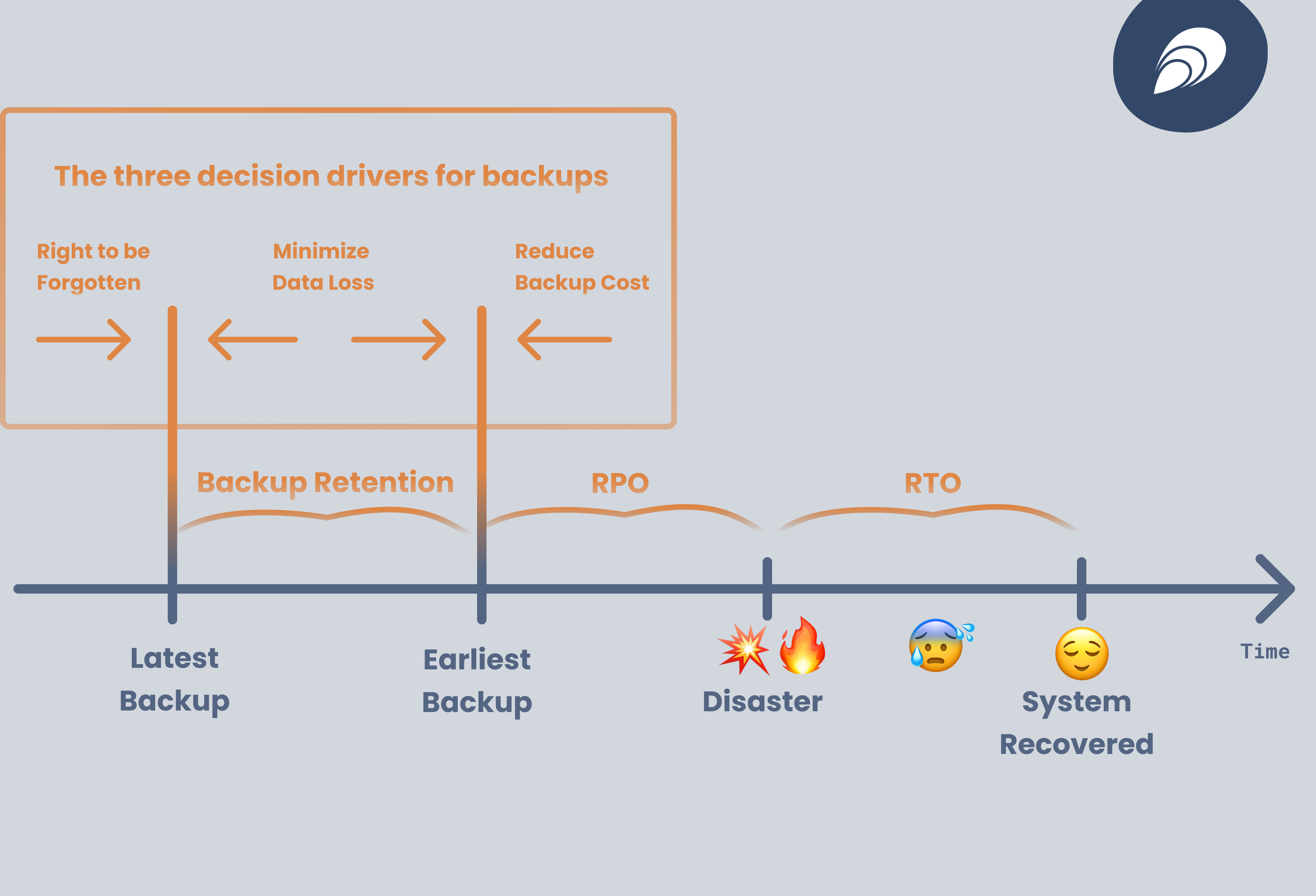
When talking about disaster recovery, one measures three parameters: Recovery Point Objective (RPO), Backup Retention and Recovery Time Objective (RTO).
Recovery Point Objective (RPO) measures what is the maximum amount of data you may lose in case of a disaster. For example, assume you run nightly backups. If the data-center hosting your Kubernetes cluster catches fire right before the backup is completed, then you lost the data generated within the last 24 hours. Hence, your RPO is 24 hours. If you take backups every 6 hours, then your RPO is 6 hours. While not commonly used with Kubernetes clusters, there are techniques for constantly streaming incremental backups – i.e., backups from the last full backup – which can reduce RPO to as low as 5 minutes. RPO in essence gives the upper bound of your recovery window. Generally, the lower the RPO, the lower the risks. However, lower RPO also entails higher costs, both in terms of storage cost of the backups themselves and in terms of overhead for taking the backups.
Backup retention determines the lower bound of your recovery window. For example, if you retain 7 nightly backups, then you can restore from as far back into the past as 168 hours. Long retention reduces data loss risk, however, it causes problems with GDPR "right to be forgotten". Specifically, for data stored in the recovery window, you need to remember to forget.
Recovery Time Objective (RTO) is the amount of time in which you aim for a recovery to be completed after a disaster happens.
RPO, backup retention and RTO are decisions to be taken on an organizational level, not merely implementation details that the platform team can determine. They are generally taken by looking at applicable regulations and making a risk assessment.
There are three decision drivers to keep in mind:
- "Right to be forgotten" will push for shorter retention times.
- "Backup cost" will push for higher RPO.
- "Minimize data loss" will push for longer retention times and lower RPO.
Typical choices include a 24 hour RPO, 7 days backup retention and 4 hours RTO.
Building Blocks for Backups
When designing backup for a Kubernetes platform, be mindful that there are really two high-level approaches: use application-specific backup; use application-agnostic backup. Application-specific backup – if available – tends to be smaller and faster. The application knows best the semantics of its data and how to avoid backing up redundant data. On the downside, application-specific backup is – as the name suggests – application-specific, hence the platform team needs to implement and train a solution for each application, which adds overhead.
Application-agnostic backups try to use a "one size fits all" solution. For example, Velero can be used to back up PersistentVolumes of any application running inside a Kubernetes cluster. This reduces tooling sprawl, but backups tend to be a bit larger. For example, by default, Grafana stores dashboards into an SQLite database. If a large amount of dashboards are removed, then the associated SQLite file keeps its size, but is filled with "empty" pages, which still use up backup space.
Application-specific and application-agnostic backups can be combined based on the skills and needs of the platform team.
For backup storage, we recommend standardizing on S3-compatible object storage. Why? Object storage has the following advantages:
- More reliable: object storage offers a simpler API than a filesystem, hence object storages tend to be simpler and more reliable.
- Cost-effective: object storage tends to be cheaper, since it is a very thin layer on top of disks and doesn't need fully-featured CPU and memory-hungry VMs.
- Simpler synchronization: object storage only allows "full object writes", hence simplifies synchronization, e.g., to off-site locations.
- Available: object storage is widely available, either on US cloud providers, EU cloud providers and on-prem.
The diagram below illustrates typical building blocks for backups.

Protection of Backups
Too often, companies end up paying the ransom of a ransomware attack, due to two reasons:
- Unknown or unacceptably high RTO. If one were to trust the attackers, then paying the ransom would reduce RTO to zero.
- Insufficiently protected backups. The attackers rendered backups unavailable, so paying the ransom is the organizations only choice for disaster recovery.
To avoid the latter, it is important for the Kubernetes platform backups to be sufficiently protected. The following methods can be used:
- Object lock: Configuring the object storage with object lock ensures that an object – i.e., the backup – cannot be removed or modified before a certain time window passes.
- Off-site replications: A script can regularly copy backups from one location to another.
- Off-cloud replications: A script can regularly copy backups from one cloud provider to another.
Object lock, off-site and off-cloud replication can be combined to maximize backup protection. In case of off-site or off-cloud backups, it makes sense to encrypt these to ensure data cannot be exfiltrated via backups. Rclone can be readily used for this purpose.
How to Conduct Disaster Recovery Drills?
Simply stating "let’s do disaster recovery" is not enough. A disaster recovery needs to be carefully planned. In particular, the following questions need to be answered:
-
What should the disaster recovery drill achieve? Examples include:
- Verifying backup scope;
- Clarifying backup demarcation between application team and platform team;
- Increasing platform team confidence;
- Making sure documentation is up-to-date;
- Measuring RTO.
-
Who should be part of the disaster recovery drill?
- Inviting the whole platform team might be overkill, so perhaps only a part of the team should be involved on a rotating basis.
- Consider having joint drills with the application team.
-
What should be the state of the environment before the disaster?
- Make sure to include a realistic application. Training how to recover an empty Kubernetes platform defeats the purpose of disaster recovery drills. Perhaps the application team can help.
-
What is the scenario?
- What caused the disaster? For example: "We will kill the VMs hosting Thanos." or "We will assume a complete loss of one data-center, and need to recover to a new data-center."
- How did the platform team find out about the disaster? For example: "We have received a ticket that the application team lost metrics. Please investigate and restore the metrics."
- Who should lead the disaster recovery?
- Who should observe and help out disaster recovery?
The disaster recovery drill should include a retrospective, which answers three questions:
- What went well?
- What to improve?
- What action items are needed for making the necessary improvements?
The platform team can then systematically work on the action items to continuously improve the disaster recovery posture of the Kubernetes platform.
Common Disaster Recovery Issues
Let us share the most common issues we discovered during disaster recovery drills:
- Application team was uncertain about the backup scope, e.g., which databases and which PersistentVolumeClaims are backed up.
- Application sometimes crashes if restored from backups and needs a few manual recovery steps.
- Velero does not restore the service account token in certain conditions (see example) which may break integration with a CI/CD pipeline.
- Velero restored resources in the "wrong" order, e.g., Deployments before NetworkPolicies. Some security-hardened Kubernetes distributions, including Elastisys Welkin, do not allow creation of Deployments that are not selected by a NetworkPolicy.
Alerts and disaster recovery equip your platform team with tremendous confidence and empowers them to make high-paced changes while risking little downtime and zero data loss. The next section will discuss the most important – and perhaps also the most neglected – changes that a platform team needs to make.