As recently highlighted by the Swedish Authority for Privacy Protection (IMY), data breaches are on the rise in particular in the healthcare sector. Part of keeping personal data safe is vulnerability management, i.e., ensuring security patches are applied throughout the whole tech stack. While many organisations are doing a great job patching their application dependencies, all that effort risks being wasted if the underlying Kubernetes cluster is left unattended.
In this post, we will highlight how you can keep your Kubernetes cluster patched. Part of the solution involves rebooting Nodes, which may be disruptive to the application. Through empathy and technical solutions, we highlight how administrators and application developers can collaborate to keep the application both up and secure.
Vulnerabilities in a typical Kubernetes Stack
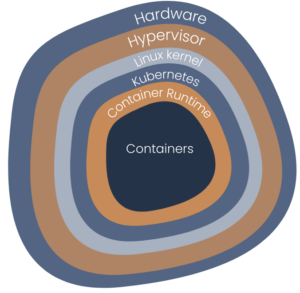
Layers. Onions have layers. Ogres have layers. Onions have layers. You get it? We both have layers. – Shrek
Vulnerabilities – also called security bugs – are weaknesses in the tech stack that – if left unchecked – can be used to compromise data security. Let us look at the various tech stack layers from metal to application, and review which ones need security patching.
Hardware
First, you have the hardware – CPU, memory, network, disk – tireless transistors pushing bits to the left and right. Fortunately, hardware doesn’t really feature vulnerabilities … except when it does. For example, memory used to be vulnerable to row hammer; CPUs to the likes of Spectre – not to be confused with Alan Walker’s song – and Meltdown.
Impact: Much of the software above relies on the hardware for enforcing security boundaries. If this doesn’t work properly, your whole security posture falls like a house of cards.
Hypervisor
The Hypervisor ensures that Virtual Machines (VMs) running on the same server are well-behaved and isolated from one another. Unfortunately, this layer has also seen its share of security bugs. For example, both qemu and VMware ESXi used to have several escape VM vulnerabilities.
Impact: In public clouds, VMs on the same server typically belong to different cloud customers. An attacker managing to escape a VM can potentially steal data from your VM.
Linux Kernel
The Linux kernel enforces containerization, e.g., making sure that each process gets its own network stack and filesystem, and cannot interfere with other containers or – worse – the host network stack and filesystem. Unfortunately, just the next 6 months have seen 3 escape container vulnerabilities (one, two and three).
Impact: Escape container vulnerabilities allow an attacker to move laterally. Once they manage to exploit a vulnerability in one application component they can get a hold of another application component, completely bypassing NetworkPolicies.
Kubernetes and Container Runtimes
Without getting into too many details, Kubernetes and container runtimes also regularly feature security bugs.
The consequences are always the same, a weaker application’s security posture. Each vulnerability is like a door left unlocked. If not treated properly, eventually an attacker can get their hands on precious data.
Why reboot Kubernetes Nodes?
Patching an application in Kubernetes is rather simple. Change the image in the Deployment to trigger a zero-downtime rolling update. But what about the underlying Kubernetes cluster, the VM Linux kernel, the hypervisor and the hardware’s firmware?
First, let’s make a distinction between applying a security patch and actually making sure the patch is live. Say I downloaded and installed a new qemu binary. Does it mean that my hypervisor is patched? No! To execute a program, its binary needs to be loaded from disk – or ROM, if we talk about firmware – into memory. So it’s not enough to download patched software, you also need to make sure that the memory image is patched. How do you do that?
Let’s start with what Kubernetes administrators control least: the hypervisor and the firmware. Cloud providers move VMs away from a server – a.k.a., they “drain” the server – patch the server, and finally reboot it. So how do cloud providers drain servers? There are two ways: either by live-migrating VMs, force-rebooting VMs or waiting for a voluntary VM reboot. Live-migration entails a non-negligible performance impact, and may actually never complete. Force-rebooting a VM allows it to be restarted on another server, but may anger Kubernetes administrators, since essentially looks like involuntary disruption, so it is rather frowned upon. Hence, the preferred method is to wait – or ask – for a voluntary VM reboot, which at the Kubernetes cluster’s level corresponds to a Node reboot.
What about the stack that Kubernetes administrators do control, like the container runtime, Kubernetes components, and VM Linux kernel? Details differ a bit on how the Kubernetes cluster is set up. If the underlying Linux distribution is Ubuntu, one simply needs to install the unattended-updates package, and security patches are automatically applied. If rebooting the Nodes is required, e.g., as is the case with a Linux kernel security patch, a file called /var/run/reboot-required is created.
The only thing left to do is … you guessed it … reboot the Node when the package manager asks.
Why can’t we avoid Node reboots with live patching?
Seems like all roads lead to proverbial Rome, i.e., you need to regularly reboot VM Nodes. Is there really no alternative?
Canonical proposes live-patching of the Linux kernel as a solution to keeping the kernel patched without needing to reboot it. The only impact on the hosted applications is a hiccup of a few microseconds. This works great for the Linux kernel, however, it is not implemented across the stack. Time will tell if this technology picks up at other levels of the stack. Will we live-patch Kubernetes cluster components in a few years?
My prediction is that we won’t see live-patching widely deployed. First, it is a complex technology. Second, “turning it off and on” is such a well-tested code path, why not use it on a weekly basis? Besides security patching, rebooting Kubernetes Nodes also acts as a poor-man’s chaos money, ensuring that the components hosted on top tolerate a single Node failure.
How to reboot Kubernetes Nodes?
Now that I convince you that you need to regularly reboot Kubernetes Nodes, let’s discuss how to do this, automatedly and without angering application developers.
Kubernetes distinguishes between voluntary and involuntary disruptions. A planned Node reboot for security patching is a voluntary disruption. In order to act nicely to the application on top, the process is as follows:
Cordon the Node, so that no new containers are started on the to-be-rebooted Node.
Drain the Node, so that containers running on the Node are terminated. This is performed so as to respect terminationGracePeriodSeconds and PodDisruptionBudgets.
Reboot the Node.
Uncordon the Node.
This process needs to be done for each Node and – quite frankly – is tedious and unrewarding. Instead, you can install the Kubernetes Reboot Daemon (kured) to do that for you. Kured watches the famous “reboot-required” file and does the operations above on behalf of the Kubernetes administrator. It uses a special lock to make sure that only one Node is ever rebooted at a time. Kured can also be configured to only perform reboots during “off hours” or during maintenance windows, say Wed 6-8, to minimise disruptions to the application.
But but but, what about the application?
A common objection to rebooting Kubernetes Nodes is that it will cause application downtime. Here we give a list of solutions, from “quick” to “thorough”:
Configure kured to reboot Nodes during off-hours, when application disruptions are less likely to be noticed. Make sure to negotiate with application developers in advance.
Observe the rule-of-two and ensure you have 2 replicas of your application. If needed, add readiness probes and topology spread constraints. Readiness probes make sure that Kubernetes understands when a new Pod is ready to receive traffic and avoids downtime due to directing traffic to an unready Pod. Topology spread constraints ensure that Pods are running on two Nodes, so that there is always a replica running.
(Advanced usage) Add PodDisruptionBugdets. This is a concept which ensures Kubernetes maintains a minimum number of replicas while draining a Node. This feature is only recommended for advanced usage, since it is easy to block Node reboots, hence compromising your cluster’s security posture. For example, running a Deployment with 2 replicas and a PodDisruptionsBudget with minReplicas 2, essentially disallows draining a Node non-forcefully.
How far down the list you need to go depends on your application. We therefore recommend going through a go-live checklist. This can be organised as a Huddle with both Kubernetes administrators and application developers. It consists of a session in which Kubernetes Nodes are rebooted and the impact is measured. If the impact is determined unacceptable, improvements can be discussed which span both application development and Kubernetes administration knowledge.
I hope I convinced you that regularly rebooting Kubernetes Nodes is necessary for a healthy security posture. It can be done both without tedious work from the administrator and without angering application developers, thanks to empathy, common understanding and a bit of Kubernetes configuration.

