Learn how Multi-Cluster Kubernetes (mck8s) uses custom Controllers to vastly improve the multi-cluster experience and how you can deploy it. The benefits? Latency-aware scheduling, cross-cluster networking, and improved resilience – greatly simplifying app deployment across multiple clouds. More? It scales Pods and Clusters horizontally, using a custom Horizontal Pod Autoscaler and the Cluster API.
Introduction
Today many enterprises deploy their workloads in multiple data centers (e.g., multiple private data centers, hybrid cloud or multi-cloud). Some of the reasons for deploying workloads across multiple data centers are high availability, low latency, vendor neutrality or compliance with regional regulations.
In the last few years, Kubernetes has emerged as the de-facto container orchestration platform because of its consistent API, portability and extensibility. As a result, several other projects that are based on Kubernetes have been popping up to address specific challenges.
One such project is Kubernetes Federation (KubeFed), which allows you to manage multiple Kubernetes clusters from a single hosting cluster. KubeFed provides low-level mechanisms that allow you to control the placement of your multi-cluster applications. However, KubeFed offers only one automated placement policy (Replica Scheduling Preference) that allows a fully load balanced or weighted placement across the selected clusters. As such, you are limited to only certain placement policies. Moreover, horizontal pod autoscaling, bursting, network traffic routing are missing from KubeFed.
That’s where mck8s (multi-cluster Kubernetes) comes in. The main objective of mck8s is to provide various resource and network-aware automatic placement policies such as worst-fit, best-fit and traffic-aware as well as offloading to nearby clusters if/when your preferred clusters run out of resources. Moreover, it provides multi-cluster horizontal pod autoscaling, inter-cluster pod bursting, inter-cluster network routing (using Cilium cluster-mesh), transparent cloud cluster provisioning, cloud cluster node autoscaling and re-scheduling features.
mck8s is developed with Python using the Kopf operator framework from Zalando. It also relies on KubeFed, Cluster API, Cilium, Prometheus and Serf.
Next, let’s discuss the details for mck8s.
mck8s Architecture
The architecture of mck8s is shown in Figure 1.
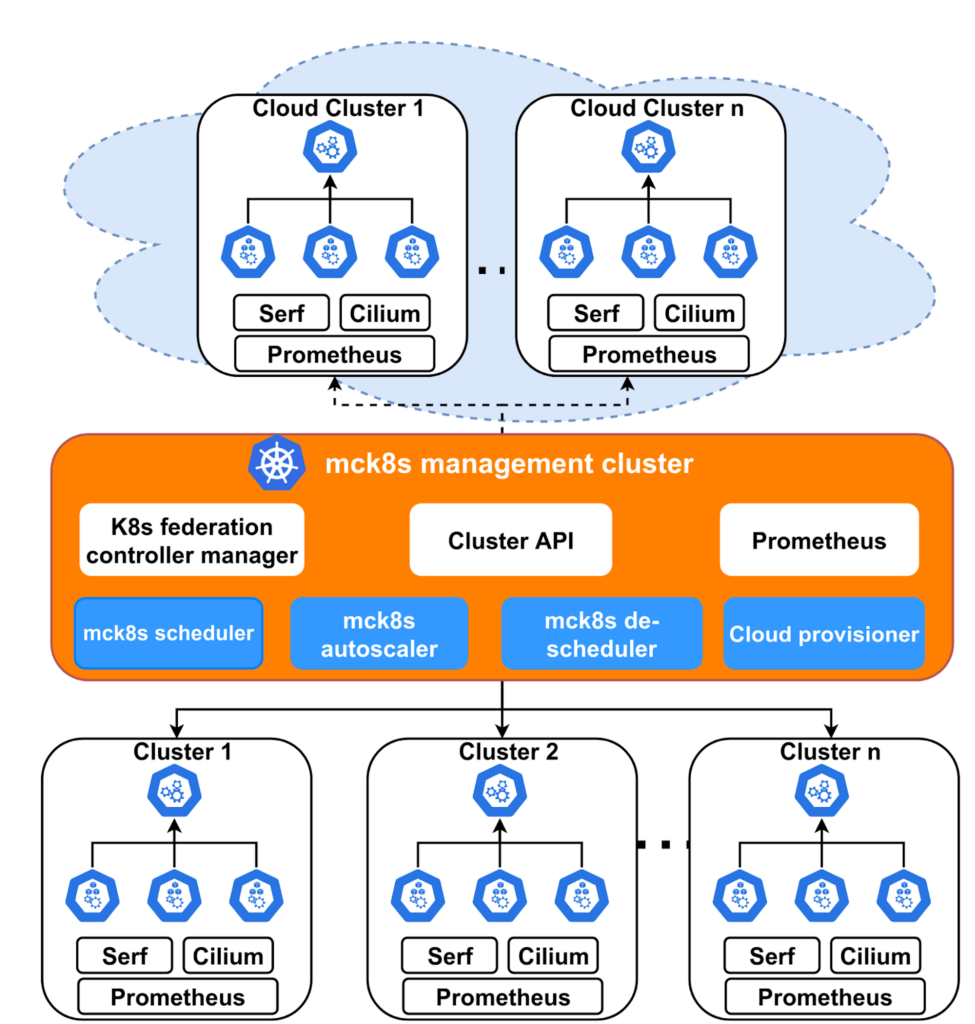
A multi-cluster environment (federation) consists of a number of workload clusters where workloads are deployed and a management cluster that is responsible for application deployment and resource management. All of mck8s’ components run on the management cluster. KubeFed is used for joining and removing clusters to and from the federation.
As monitoring is important for the functioning of mck8s, Prometheus is deployed on all workload clusters. An instance of Prometheus deployed on the management cluster aggregates all the necessary metrics from the workload clusters.
Serf is used to estimate inter-cluster network latency which is necessary for making network-aware placement and offloading decisions.
Although mck8s works with any networking providers, inter-cluster network routing is supported only with Cilium cluster-mesh. Therefore, currently we use Cilium as the network provider for the workload clusters.
Let’s now look briefly at the controllers that mck8s introduces and their functionalities.
mck8s Controllers
mkc8s introduces four controllers. As mentioned earlier, these controllers are developed with Python using the Kopf operator framework. The design of these controllers follows the Monitor-Analyze-Plan-Execute (MAPE) framework.
Each controller is deployed as a Kubernetes Deployment resource on the management cluster.
Multi-cluster scheduler
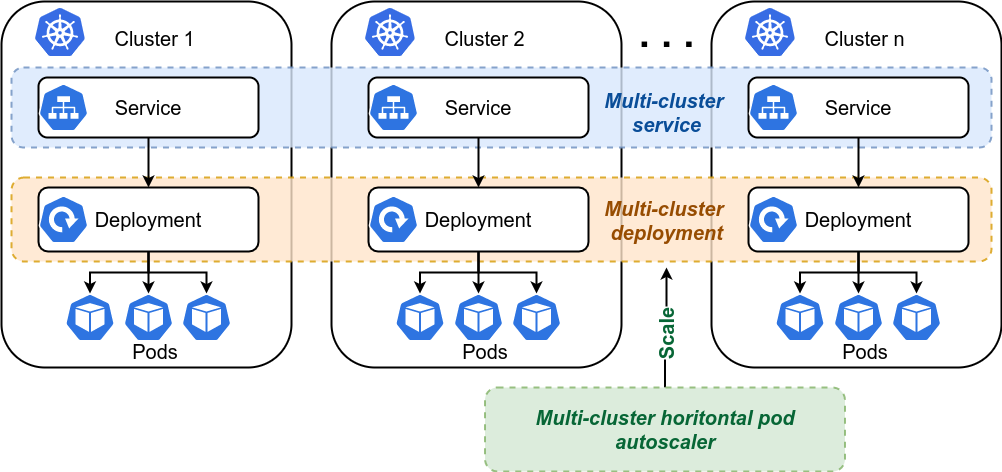
The first and most important controller is the multi-cluster scheduler which is responsible for selecting the appropriate workload clusters that can host a multi-cluster deployment (MCD). An MCD is an abstraction for a set of Kubernetes Deployments that run across multiple workload clusters but share the same name and Docker image (see Figure 2). However, different Deployments of an MCD on different workload clusters may have different numbers of replicas.
When deploying an MCD, you may specify your preferred workload clusters manually or you may select worst-fit, best-fit and network-aware placement policies, in which case the multi-cluster scheduler selects the appropriate workload clusters automatically.
During manual placement, the multi-cluster scheduler checks whether the preferred cluster(s) have sufficient computing resources (RAM and CPU cores) to host the Deployments. If sufficient resources are available, the Deployments are scheduled on the preferred cluster(s). Otherwise, the Deployments are automatically offloaded to the cluster that is closest in terms of network latency to the original preferred cluster(s).
The multi-cluster scheduler also supports overflow or bursting of Deployment replicas in which case not all but only some of the replicas of a Deployment are offloaded to nearby cluster(s).
If you have selected one of the automatic placement policies, the multi-cluster scheduler selects the appropriate clusters based on the availability of computing resources of the amount of network traffic received. For instance, if you selected the worst-fit placement policy, the workload clusters are sorted according to the available resources, and the clusters(s) with the most resources are selected for placement. In contrast, with best-fit policy the clusters with the least resources are selected first. On the other hand, if you selected a network-aware placement policy the clusters that receive the most network traffic are selected first. This last policy is interesting in the case of fog and edge computing where you may want to deploy applications close to end users using network traffic as an indicator for where they are concentrated the most.
Finally, the multi-cluster scheduler is also responsible for creating the corresponding Service resources for the MCDs in their respective clusters (see Figure 2).
Multi-cluster horizontal pod autoscaler
Of course, you wouldn’t only want to deploy your applications. You would also like them to be elastic, i.e., scale-out and scale-in automatically in response to changing user traffic. The multi-cluster horizontal pod autoscaler (MCHPA) lets you do just that (see Figure 2). MCHPA monitors MCDs periodically for resource utilization and increases their replicas if the utilization is above a certain threshold that you defined. If, on the other hand, the utilization is below the threshold the number of replicas is decreased. Thanks to the bursting capability of mck8s, applications may burst to nearby clusters during scale-out if necessary.
Cloud provisioner and autoscaler
If you are operating a private data center, there are times when it runs out of resources due to spikes in user traffic or large batch jobs. At these times you may want to provision resources from a public cloud provider just to handle the workload spike. Also, you may want to remove those public cloud resources when they are not needed anymore. Otherwise, you would be spending money unnecessarily. mck8s’ cloud provisioner does just that transparently.
If an MCD cannot be scheduled on any of the workload clusters because of lack of resources, it’s status is updated with a message. The cloud provisioner periodically checks for such messages. When it finds some, the cloud provisioner creates a Kubernetes cluster via Cluster API on one of the supported public cloud providers. After the cloud cluster is created, it joins the multi-cluster federation and the MCD is scheduled on it. This controller also autoscales the newly created cluster according to the resource utilization.
Finally, the cloud provisioner removes a cloud cluster if it doesn’t have workloads for a certain amount of time.
Multi-cluster re-scheduler
As we saw earlier, some deployments may be offloaded to public cloud clusters if the preferred clusters you chose were out of resources. As a result, you may want them to be scheduled back to the preferred cluster if possible. The multi-cluster re-scheduler periodically checks for deployments in the public cloud clusters if they can be scheduled on the preferred cluster that you specified and tries to schedule them again. This will also help keep the cost of public cloud clusters down.
Inter-cluster network routing
If you have workloads that span multiple clusters, chances are you also want the user traffic to be distributed among them. To achieve this, we use Cilium cluster-mesh in mck8s to allow inter-cluster network traffic routing and load balancing. All you need to do is to add an annotation in the manifest file of the multi-cluster service for your workload.
How to deploy your multi-cluster applications using mck8s
Once you have deployed the mck8s controllers on your management cluster, deploying your applications on your workload clusters is quite easy. For instance, to deploy an MCD on two workload clusters using the traffic-aware policy, you may use a manifest like the one in Listing 1. You may also create the corresponding Service resources using a manifest file like the one in Listing 1. Notice that the manifest files are pretty much the same as those of vanilla Kubernetes resources and the only fields you need to change are apiVersion, kind and some additional fields under spec.
apiVersion: fogguru.eu/v1
kind: MultiClusterDeployment
metadata:
name: mcd-app-1
spec:
numberOfLocations: 2
placementPolicy: traffic-aware
selector:
matchLabels:
app: mcd-app-1
tier: backend
track: stable
replicas: 5
template:
metadata:
labels:
app: mcd-app-1
tier: backend
track: stable
spec:
containers:
- name: mcd-app-1
image: "k8s.gcr.io/hpa-example"
resources:
requests:
memory: 512Mi
cpu: 500m
limits:
memory: 512Mi
cpu: 500m
ports:
- name: http
containerPort: 80apiVersion: fogguru.eu/v1
kind: MultiClusterService
metadata:
name: mcs-app-1
annotations:
io.cilium/global-service: "true"
spec:
selector:
app: mcd-app-1
tier: backend
ports:
- protocol: TCP
port: 80
targetPort: http
Conclusion
In conclusion, mck8s offers many nice features that automate the deployment of your workloads across the multiple clusters that you operate. To read more about mck8s, please check out our paper accepted at the 30th International Conference on Computer Communications and Networks (ICCCN 2021). You may also take a look at the source code on github for more deployment examples.