Joel Sandman recently conducted his Master thesis research project at Elastisys. In this blog post, he summarizes his work on evaluation of different caching methodologies for microservice-based architectures in Kubernetes.
Introduction
My thesis evaluates and compares different caching methodologies in microservice-based architectures. The three methodologies which are compared are no caching, full-page caching of the end response of the system, and fine-grained caching which is installed in between the services of the system. What can be gained by introducing caches to such a system is, among other things, a reduction in network traffic. However, this comes for a cost in data staleness and extra memory usage.
Community or Business Value
If the best performing caching methodology is installed in a microservice-based application, the network traffic reduction might be significant compared to if another caching methodology was to be used. Therefore, it is highly interesting to compare how the different methodologies compare to each other with respect to the above mentioned metrics, namely network traffic reduction, data staleness, and memory usage. This comparison and evaluation is what I am presenting in my thesis, and my hopes are that it will aid developers in choosing how to handle caches in their microservice-based applications, as well as to inspire them to use caches at all by demonstrating the potential benefits of them.
Experimental Design and Setup
To perform the experiment, I started by installing a microservice-based application, known as Online Boutique, which is an example web shop with a built-in load generator. Since all data in the web shop was completely static, I re-programmed two of the services to update their data at certain frequencies. I did this to introduce the stale data problem to the system. Apart from that I left the system unaltered. I also implemented a cache component which intercepted outgoing requests from microservices and cached them. For every request, it also checked whether the response for that request was already in the cache, and if its time-to-live (TTL) had not expired. Regardless of whether the response was in the cache or not, the request was always sent to the intended recipient. This was done to be able to control whether the response in the cache was fresh or stale. However, if the response was found in the cache, that response was always returned, even in the cases where it was found to be stale. The cache component was implemented both for HTTP and gRPC traffic, used for the full-page and fine-grained caching respectively. The latter intercepted the requests using a modified protobuf.
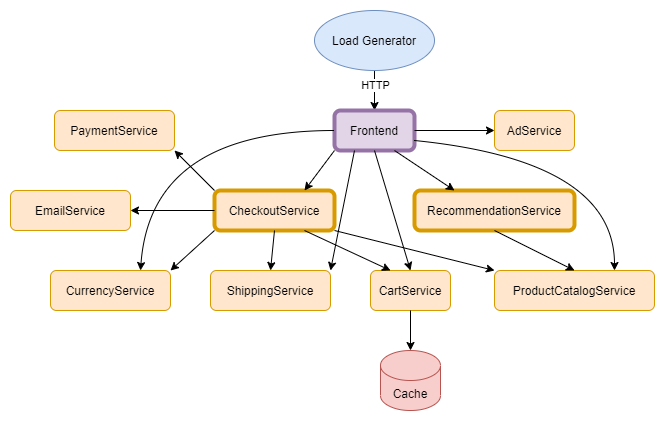
For the full-page caching, I only installed the cache component on the frontend service, whereas for the fine-grained caching the cache component was installed on all services which sent requests to other services within the system, marked with bold borders in the figure. All cache components logged information about each request, such as whether they were found in the cache and if they were fresh or stale. They also logged information about the memory usage of the cache every other second. The load generator was used to simulate 100 users browsing the web shop.
The experiment was also run with several different TTLs, to compare how the difference in TTL affected the results, and each combination of caching methodology and TTL was run five times to minimize the risk of temporary anomalies affecting the results.
Results
The results I got was that the fine-grained caching acquired a higher network traffic reduction for all different TTLs. It also had a lower relative data staleness for all TTLs, as well as a lower memory usage.

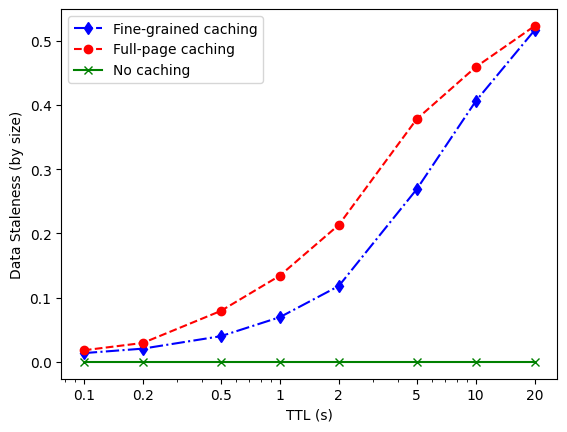
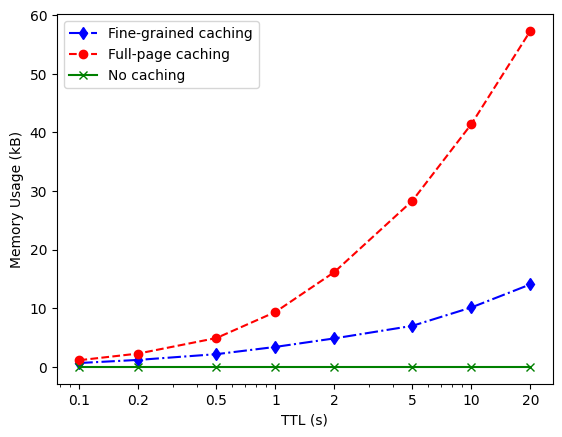
Also, when calculating the quotient between the network traffic reduction and the data staleness, the fine-grained caching always performed better. This was calculated to be able to draw conclusions about at which TTL the best trade-off between the two metrics would be found, in my system. The numbers in the tables can be seen as a score of how much reduction in network traffic that can be acquired for what cost in data staleness. As can also be seen is that the score of the full-page caching is also exactly one, indicating that the data was always stale.
| TTL | Full-page | Fine-grained |
| caching | caching | |
| 0.1 | 1.00 | 7.09 |
| 0.2 | 1.00 | 8.30 |
| 0.5 | 1.00 | 6.68 |
| 1 | 1.00 | 5.51 |
| 2 | 1.00 | 4.31 |
| 5 | 1.00 | 2.40 |
| 10 | 1.00 | 1.78 |
| 20 | 1.00 | 1.54 |
Such a quotient was also calculated for the memory usage compared to the network traffic reduction, and also here the fine-grained caching performed better at each TTL.
| TTL | Full-page | Fine-grained |
| caching | caching | |
| 0.1 | 7.41 | 3.90 |
| 0.2 | 7.05 | 3.10 |
| 0.5 | 5.86 | 3.52 |
| 1 | 6.38 | 3.62 |
| 2 | 6.89 | 3.91 |
| 5 | 8.29 | 4.36 |
| 10 | 9.12 | 5.74 |
| 20 | 10.79 | 7.23 |
Interpretation of Results
What can be seen in the results is that, in my system, the fine-grained caching methodology performed considerably better than the full-page caching in all aspects and for all different TTLs. However, since the full-page cache component only served stale data I took a closer look into why this was the case. What I found was that the most likely reason for this is that the recommendation service serves four random recommendations for each page on the web shop, and as long as the recommendations differ from the recommendations in the cached response, the response is considered stale. I did not want to change the experiment as an effect of the results, and also it is my opinion that this showcases one of the biggest flaws of the full-page caching methodology; that as long as any service or data in the system has changed or answers differently, the data in the cache will not be the same as if you were to call the system anew.
Conclusions
The results of my experiment shows that, at least in my system, a 17% of network traffic reduction could be acquired by introducing a data staleness of only 2% and by using very little extra memory, using the fine-grained caching methodology and a static TTL of 0.2 seconds, which was the TTL with the best quotient in all aspects. If a little more data staleness could be acceptable and a little more extra memory be spared, using the fine-grained caching with a TTL of 1 second achieved a network traffic reduction of 40% for a cost of less than 7% in data staleness.
Of course these exact numbers only apply to the specific system in which I have performed my experiment, but due to the clear results it is my strong conviction that many microservice-based systems, which could accept a small amount of stale data, could profit a lot from implementing fine-grained caching.