Erik Dahlberg wrote his Master Thesis with us at Elastisys, and successfully defended it in June 2020. In this blog post, we share the major outcomes of his work. With close ties to academia, Elastisys is a great place to do your Master Thesis work. Please contact us if you want to do like Erik did and dive deep into a cloud-native technology!
Key takeaway messages
- For most intents and purposes, Istio and Linkerd offer equivalent feature sets.
- Istio has a stronger multi-cluster story than Linkerd does.
- Istio has a significantly larger community and thought leadership position.
- Our benchmark results show that Istio consumed more memory, but added less latency.
- Linkerd also seemed to reach some internal limitation sooner than Istio, however, the root cause of this was not analyzed.
Motivation
Service mesh is a relatively new subject that has grown in the microservice community over the last few years. To date, there exist multiple service mesh implementations with different architectural approaches ranging from smaller open-source projects to major endeavours being backed by big companies such as Google. This introduces questions about how mature the current service mesh projects are and what performance impact they have.
Thesis goals
The goals of this thesis have been to analyze services meshes based on the following criteria:
- Features: analyze feature sets
- Maturity: analyze the overall project maturity
- Ease of use: describe the process and ease of deploying the service mesh into already existing microservice application
- Performance: evaluate the overhead introduced by integrating a service mesh into a microservice application
Background: what is a service mesh?
Trying to describe service mesh in one sentence – “A service mesh is a mesh of useful/necessary features bundled together in a way so they can be applied to your application without the need of doing any code modification (features that you probably needed anyway)”. One example of this is resilience features, “probably” needed for every service you are to create. Instead of rewriting resilience libraries for every service in your application, yes services (they can be in different languages). You instead throw a service mesh in the mix and it’s done without modifying your service. So now you probably asking yourself, what is this magic? It’s actually a pretty easy solution.
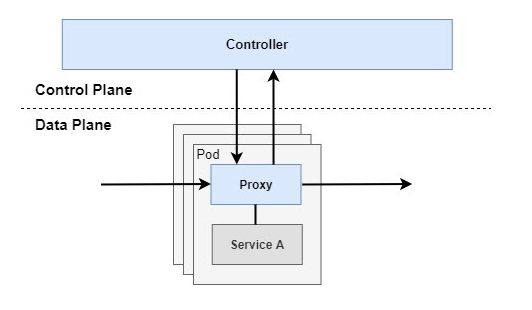
A services mesh works by intercepting all communication to and from a service. Traffic interception is usually done by deploying proxy instances beside each service, so called sidecar injection, referring the proxy as the sidecar. This allows the service mesh to intercept and manage traffic without application modification. This enables key features such as metric gathering (e.g. latency, error rate), traffic management (e.g. splitting traffic between services, replicating traffic for testing), security (applying authentication and encrypted communication between services with mTLS) and resilience (e.g. retries, timeouts and circuit braking). The behavior of the proxy instances are steered by a set of management components referred to as the control plane. All proxies running alongside the services in the mesh are usually referred to as the data plane.
A good article describing why service mesh are useful that also talks about how they work is, “The Service Mesh: What Every Software Engineer Needs to Know about the World’s Most Over-Hyped Technology” by William Morgan. He is the current CEO of Buoyant and was also one of the creators of Linkerd.
Istio and Linkerd: service meshes selected for this thesis
For finding services meshes to compare I used the Cloud Native Landscape, which is available at the Cloud Native Computing Foundation (CNCF). This site is a resource map to help enterprises and developers to find cloud-native technologies. The service meshes presented by the Cloud Native Landscape can be seen below. Istio was selected due to its popularity (most GitHub stars). Linkerd due to its architectural design being similar to Istio and for being hosted by CNCF.

Istio
Istio is an open-source project publicly released for the first time in May 2017 by Google, IBM and Lyft. Its architecture follows the common approach of using sidecars to integrate into a microservice application. The architecture is divided into two main parts, a data plane and a control plane. The data plane represents the sidecars, intercepting and managing all network communication between services. The control plane manages and configures the behavior of data plane and the service mesh.
Linkerd
Linkerd was for the first time released in 2016 by Buoyant. It was later to be redesigned and rewritten in Rust and Go for Kubernetes to lower the resource footprint and create a simpler solution. This newer version was introduced in December, 2017 as a separate service mesh project called Conduit. Conduit was later on July 6, 2018 merged into the Linkerd as a separate Linkerd project creating Linkerd 2.0. This thesis henceforth studies Linkerd 2.x and refers to it as Linkerd.
To date, Linkerd only supports Kubernetes and actually requires it to run compared to Linkerd 1.x that supports multiple environments. The Linkerd architecture is based on the sidecars principle mentioned earlier. The architecture is divided into two parts: the control plane and date plane, the date plane represents the proxy servers running alongside each application and intercept all communication. The control plane is split up into several services control the behavior of the data plane and collect telemetry about the network and service mesh.
Feature comparison: Istio vs. Linkerd
Linkerd is explicitly written for Kubernetes, to date only supporting Kubernetes. Istio is designed to run in any environment claiming to be platform-independent. To date, Istio runs on Kubernetes, Consul (alpha phase) and individual virtual machines (they can be connected into an existing Istio mesh deployed on Kubernetes).
Both meshes provide observability by using web-interfaces (dashboard) and preinstalled Grafana dashboards. Grafana is used to display information stored in the Prometheus datebase (e.g. CPU/memory of each pod and container). The web-interface is used to display and interact with the mesh, showing inject/uninjected pods and communication between services. Displaying golden metrics such as success rate, traffic (requests per second), latencies and saturation (system utilization). Both meshes provide distributed tracing but application modification is needed to propagate headers.
Resiliency features are also supported such as retries and timeouts, allowing the sidecar to retry failed requests and timeouts, if replies are too slow. Fault injection for introducing errors to services. Traffic shifting for dynamically shifting traffic between services. Istio also provides circuit breaking, that breaks all connection to a service after a fixed amount of concurrent connections of failed calls.
Security with authentication and encryption with mTLS are supported by both meshes. Linkerd automatically enables mTLS for most HTTP traffic, some gaps (e.g. Host header in HTTP request is an IP address). Istio has a strict mode that can be toggled to allow only traffic with mTLS or both mTLS and plain-text.
A shorter list of some of the features provided by both meshes:
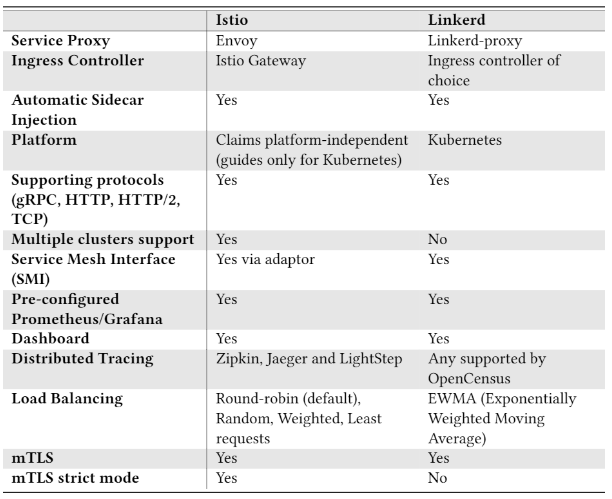
For a more thorough and up to date list that also compares other services meshes, see https://servicemesh.es/.
Project maturity: Istio vs. Linkerd
Both projects give a mature feeling by both having an increasing community growth with an established community governance.
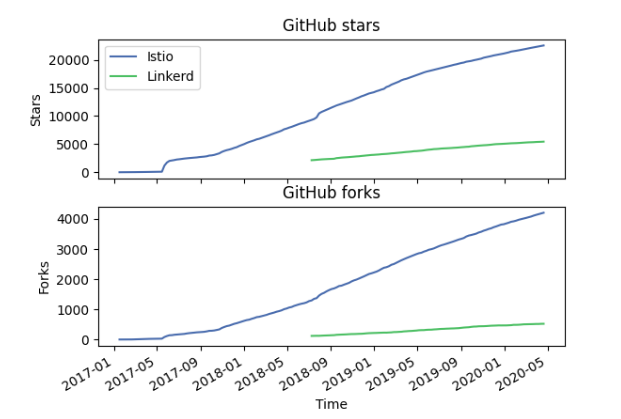
Istio has, to date, 22.8 thousand stars and is steered by their Steering Committee formed to oversee the administrative aspects of the project, including governance, branding, and marketing. The committee has 10 seats held by companies currently from IBM (3 seats), Google (6 seats) and Red Hat (1 seat). They also determine the members of the Technical Oversight Committee (TOC), responsible for project oversight, direction and delivery. The community is organized into working groups focusing on a specific area (e.g. documentation and security).
Linkerd has, to date, 5.5 thousand stars and is hosted by the CNCF project. The governance is split up into two roles, maintainer (8 people) and super-maintainer (2 people). Maintainer oversees one or more components, handling pull requests, sorting issues, etc. Super-maintainers oversee the project, guiding the general project direction. Project decisions are resolved by consensus otherwise the majority vote by the super-maintainer and maintainer. Maintainers are voted in by a 2/3 majority organization vote.
The trajectory of GitHub stars and forks from Istio and Linkerd can be seen in the figure below. Displaying an increase for both meshes since their release at GitHub. Istio has had a more rapid increase than Linkerd, especially when Linkerd actually is older than Istio with the predecessor Linkerd 1.
Ease of use: Istio vs. Linkerd
Both meshes support deployment with command line interface (CLI) and Helm for deployment. This with automatic sidecar injection makes both meshes fast and easy to deploy, without any application modification. Both meshes can actually be deployed with just CLI commands, first for deploying the mesh and secondly for injecting sidecars. Services injected with side-cars can both be seen through kubectl and provided service meshes dashboard.
Benchmarking performance: Istio vs. Linkerd
Benchmark setup
To evaluate the performance of the two meshes, a testbed was created. The testbed is deployed in a Kubernetes cluster on Google Kubernetes Engine (GKE) consisting of five n1-standard-4 virtual machines, each having 4 vCPUs and 15 GB memory. The benchmark is ran three times: without service mesh (reference point), with Istio version 1.5.0 and with Linkerd version 2.7.1.
Both service meshes provide a range of features that can be toggled on and off for tuning and performance purposes. However, for fair comparison, they were in stock configuration following installation from their ”Start Guide”. Istio has a set of predefined configuration profiles, the current one used is called ”demo”.
The testbed consists of three parts: load generator, test application and a metric collection unit. All deployed in the same GKE cluster to produce results with less noise. The test application is a micro-service application called TeaStore, emulating a web store for browsing and shopping tea supplies. Teastore consists of seven services (referring to the datebase as a service) each deployed in a separate pod. Each service is deployed on a specific node using nodeSelector. This guarantees that each pod is always deployed on the same node between benchmarks (redeployment of application pods are needed when switching between service meshes). The application is reached through the front-end which is the WebUI hosting the website.
Load is generated with the load testing tool Apache Jmeter. Load is generated by a specified number of users, each iterating over a list of 8 different HTTP requests, emulating users browsing and using the store. Each user is set to produce a constant throughput of requests. Latency is measured from Jmeter and CPU/memory is gather with node exporter and Prometheus.
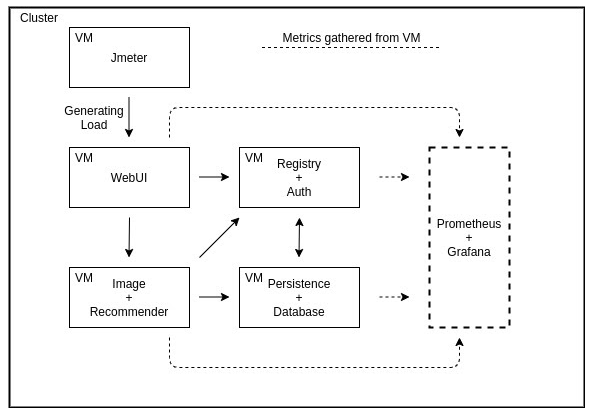
The benchmark ran 3 times like I mentioned before. Each benchmark consists of 5 runs ranging from 5 to 40 users (5, 10, 20, 30, 40). Each user is set to create a constant throughput of 5 requests per second (RPS). Each benchmark starts with a warm up for 3 minutes with 20 users generating a constant load for the application, to warm-up TeaStore caches, etc. Each benchmark is running 14 minutes per user group, with a waiting period of 5 minutes between user groups.
Performance benchmark results: Istio vs. Linkerd
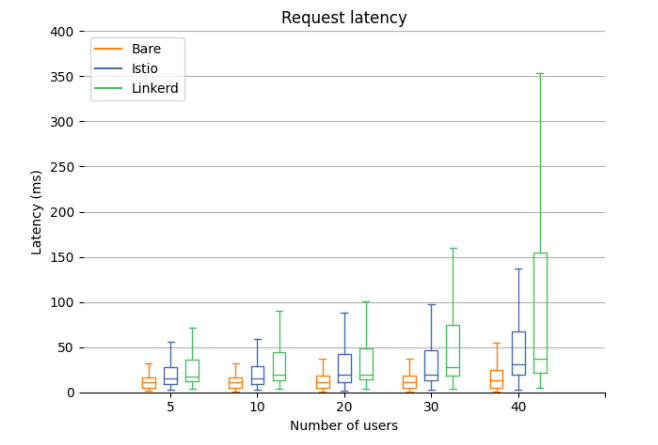
Latency
The latency (time to first byte) are gathered from all request types, presented in milliseconds. Comparing both to Bare (no service mesh) makes it clear that both meshes add latency. In the 75th percentile at 20 users the increase between Bare(18 ms) and Istio(42 ms) is 133%, compared to Linkerd’s (49 ms) 175% increase. Istio seems to overall perform better with less latency overhead compared to Linkerd. It can also be seen that the latency for Bare increases at a slower rate with the number of users compared to the service meshes.
Also worth mentioning that you can neglect the large increase for Linkerd at 40 users, will talk about this in the conclusion.
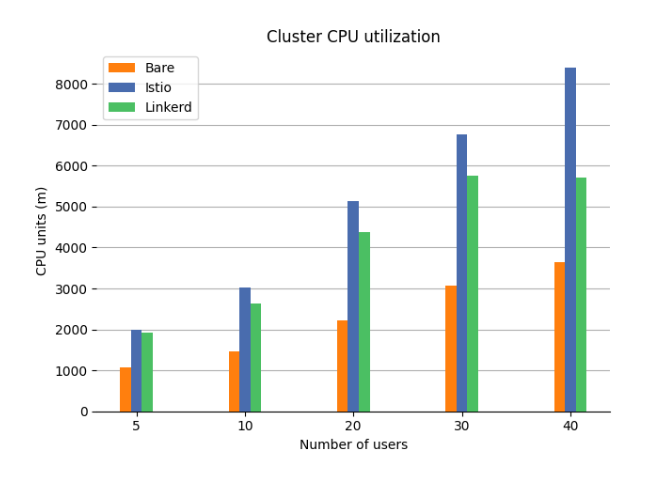
CPU utilization
The CPU Utilization is gathered from the complete cluster (except nodes with Jmeter), the total amount available is 20 vCPU (20000m). The unit m stands for ”thousandth of a core”, 1000m is equivalent to one core. At 20 users the CPU utilization increase between Bare(2226 m) and Istio(5132 m) is 131%, compared to Linkerd’s (4386 m) 97% increase. Showing that Istio uses more CPU compared to Linkerd and that both consume more than Bare.
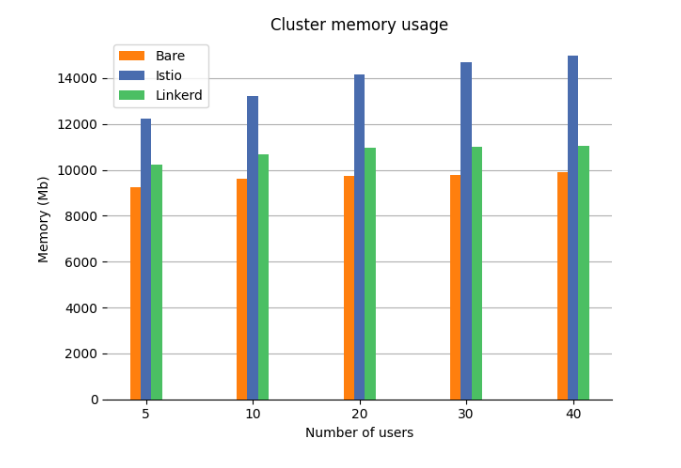
Memory usage
The memory usage is gathered from the complete cluster (except nodes with Jmeter), the total amount available is 60000 megabytes. At 20 users the memory usage increase between Bare(9749 MB) and Istio (14152 MB) is 45%, compared to Linkerd’s (10947 MB) 11% increase. It can also be seen in the figure that Istio memory consumption seems to increase with the number of users. Showing that Linkerd has a clear advantage when it comes to memory consummation.
Conclusions
Overall, both service meshes perform well, offering a good range of features, ease of use and a mature community. Istio is more popular providing more features and has a slightly upper hand in terms of latency, making it the best choice if performance and future support outside Kubernetes are important. Linkerd provides better resource consumption making it a better choice for machines with less computational power or if the added latency is less important. It can also be worth mentioning that Google currently controls Istio (having majority in the board) and that Linkerd is hosted by Cloud Native Computing Foundation (CNCF). There have been some concerns if Google is going to give Istio to a nonprofit foundation or not. Google has also mentioned that they will in a near future give away Istio.
It needs to be mentioned that Linkerd was not able to maintain the wanted throughput of 40 users, resulting in a higher latency and lower CPU utilization at 40 users. The effect seems to be similar to a CPU bottleneck, where the maximum throughput is higher at the point before the CPU reaches its limit. This might be some type of resource limit in Linkerd, because none of the nodes during the test was close to reaching 50 percent CPU utilization.